计划
简单介绍关系型数据库的各个组成部分。
- 关系模型发展历史
- 内存管理器
- 索引简介
- 事务管理器
- 故障恢复
通过marp制作的演示版本
从成绩管理开始…
你的C语言老师给你布置了一个任务: 要求编写一个程序:
- 能够存储学生的学号、姓名、年龄、C语言课的成绩
- 能够统计出成绩最大最小值,平均值。
- 能够找到给定学号学生的成绩。
于是你通过已有知识,写出程序
首选确定需要存储哪些信息
typedef struct /*存储学生信息的结构体*/
{
char stu_name[32]; /*存储姓名*/
char stu_num[32]; /*存储学号*/
int stu_age; /*存储年龄*/
int stu_point; /*存储成绩*/
int stu_year; /*存储入学年份*/
int stu_gender; /*存储性别*/
} Student; /*管理学生结构体名字为Student*/
你实现了磁盘存储…
FILE *outfile = fopen("stuinfo.txt", "w"); /*打开文件*/
fprintf(outfile, "%d\n", tot_stu_num);
while (num < tot_stu_num)
{
/*将信息按照顺序输出到文件*/
fprintf(outfile, "...", student_info[num].stu_name,...)
num++;
}
fclose(outfile); /*关闭文件指针*/
将信息存储在"stuinfo.txt"中。
你实现了统计函数
MIN,MAX,SUM,AVERAGE…
void max_point()
{
int ans = student_info[0].stu_point; /*ans为临时的最大值*/
int num = 0;
while (num < tot_stu_num)
{
/*如果当前分数大于临时最高分,更新*/
if (student_info[num].stu_point > ans)
ans = student_info[num].stu_point;
num++;
}
printf("最高分是%d\n", ans);
}
你实现了C语言老师的要求,但是…
此时你的微积分老师来了,表示:
我也要用你这个程序来统计我的学生成绩
于是你只有修改学生结构体,随之而来的是所有函数的修改。
包括读写函数,统计数据的函数。
typedef struct /*存储学生信息的结构体*/
{
char stu_name[32];
int stu_c_point; // C语言成绩
int stu_math_point; // 微积分成绩
...
} Student;
麻烦接踵而来
-
如果电脑在修改数据时崩溃了,会怎么样?
- 比如老师将100分制改为了5分制。
- 然后班上有100位同学,修改了50位同学的数据时,电脑宕机了。
- 导致有50个4分的同学,与50个100分的同学。
-
如果有你的一个C语言老师在修改成绩,另一位C语言老师也开启了该程序,并读取成绩。是否会发生冲突。
-
如果现在全国100万个学生的成绩都要通过该程序录入
- 查询一位特定学生的成绩需要多久?
- 程序需要多少运行内存?
关系模型的提出
-
Edgar Frank Codd 埃德加·弗兰克·科德 1969年的一篇论文,提出了关系模型
-
从表(Table)及表的处理方式中抽象出来的,是在对传统表及其操作进行数学化严格定义的基础上,引入集合理论与逻辑学理论
-
关系模型的三个要素
-
基本结构:Relation/Table
-
基本操作:Relation Operator(例如:交∩、并∪、差-、投影π等等)
-
完整性约束:实体完整性、参照完整性和用户自定义完整性。
-
- 我们把一行叫做一个元组。tuple/record/row。一行数据,一条记录
关系代数
| 符号 | 名称 |
|---|---|
| σ | Select |
| π | Projection |
| ∪ | Union |
| ∩ | Intersection |
| – | Difference |
| × | Product |
| ⋈ | Join |
-–
Select
从集合中选出一个满足条件子集
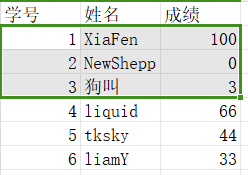
例如
- $Select_{学号\le3}(学生成绩表)$
- $Select_{姓名=XiaFen}(学生成绩表)$
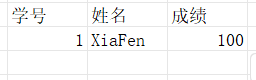
Projection/投影
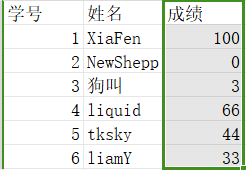
$Π_{成绩}(R)$
并集
SQL中的UNION ALL可以保留重复
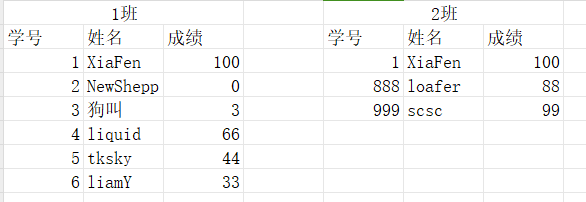
(SELECT * FROM 1班) UNION ALL (SELECT * FROM 2班);
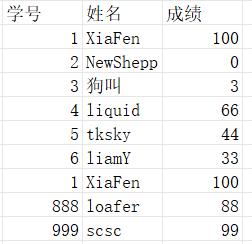
Intersection/交集
$(1班 ∩ 2班)$
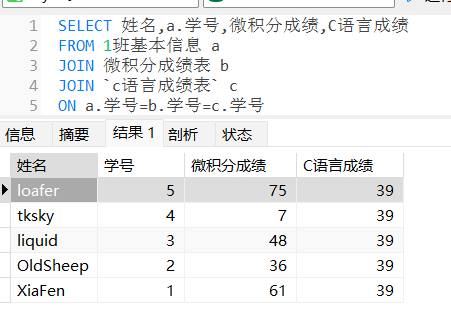
JOIN/连接 (R ⋈ S)
假如现在1班将姓名和成绩分表存储。(因为可能有多个科目)
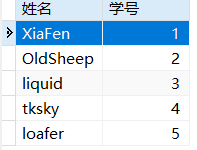
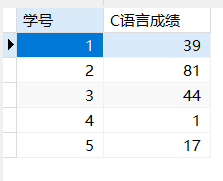
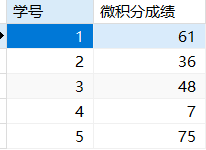
- SELECT * FROM 1班基本信息 JOIN 微积分成绩表 USING (学号);
-–
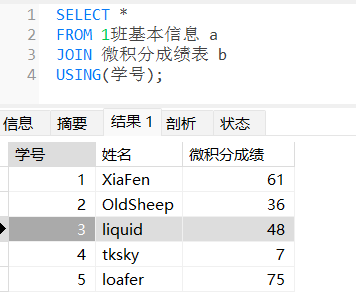
你也可以将多个关系代数组合
例如 $Π_{姓名,学号,微积分成绩,C语言成绩}((1班基本成绩⋈微积分成绩)⋈C语言成绩)$
还有更多的关系代数…
– Difference 差集 × Product 笛卡尔积 ρ Rename 重命名 R←S Assignment 赋值 δ Duplicate Elimination 去重 γ Aggregation 聚合 τ Sorting 排序 R÷S Division 除法
数据的组织
- 磁盘文件的结构
- 页面的结构
- 元组的结构
数据存储在?
- DDR5: 100GB/s
- SSD: 3GB/s
- 固态硬盘: 50MB/s
- 手摇硬盘:?
数据分页
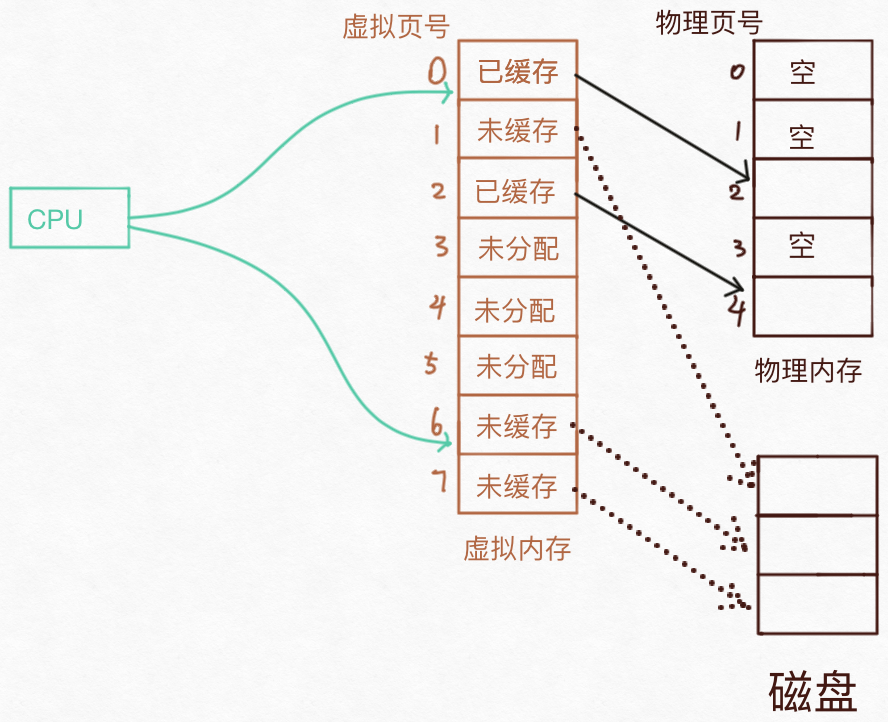
操作系统从最开始的内存分段、内存置换、到虚拟内存,段页模式。
将虚拟地址空间分成若干个块,每个块都有固定的大小,物理地址空间也被划分成若干个块,每个块也都有固定的大小,物理地址空间的块和虚拟地址空间的块大小相等,虚拟地址空间这些块就被称为页面,物理地址空间这些块被称为帧。
关于分页这里有个问题,页面的大小是多少合适呢?页面太大容易产生空间浪费,程序假如只使用了1个字节却被分配了10M的页面,这岂不是极大的浪费,页面太小会导致页表(下面介绍)占用空间过大,所以页面需要折中选择合适的大小,目前大多数系统都使用4KB作为页的大小。
- 硬盘分页: 4KB
- 操作系统分页:4KB
- 数据库分页:512B-16KB
可以这么理解分页: 比如一个年级有1000名学生,每个班有100名学生,一共有10个班。将成绩打印出来之后,将数据分成了10页,方便查询。你也可以用一张100m的纸,但是会导致分页的浪费。
磁盘上文件的结构
- heap
- tree
- sequential
- hash
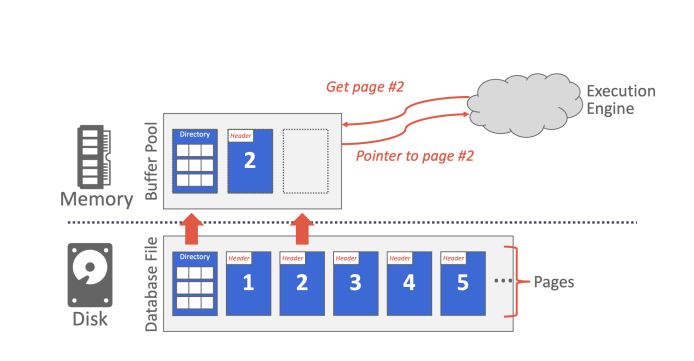
Heap File
Heap File记录不同页的位置。
不同的页可能存在于不同的磁盘空间,甚至在网络上。
一种最简单的设计是在一个文件中。
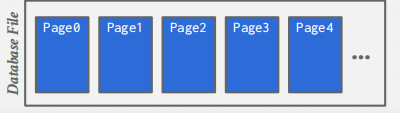
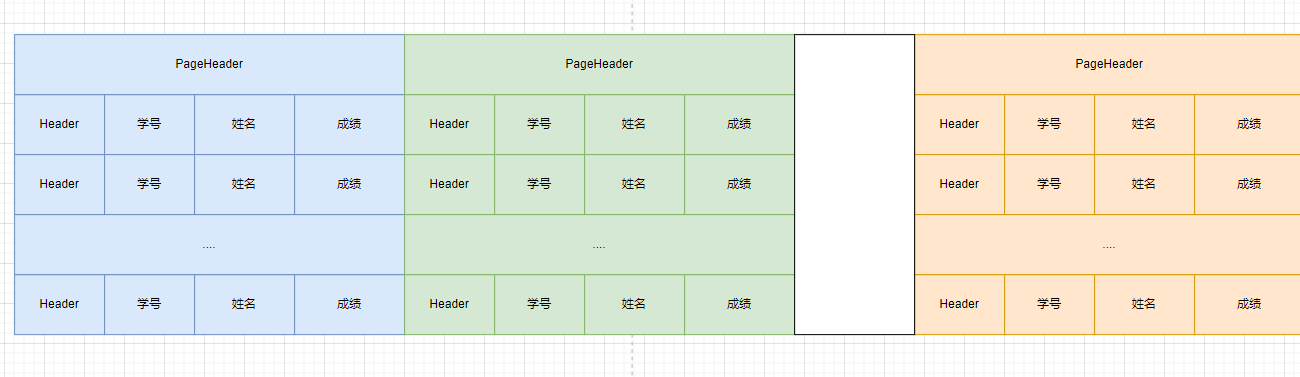
Page结构

在一个简单的设计中,我们通过页面编号和Tuple编号就能够定位一个tuple
Tuple结构
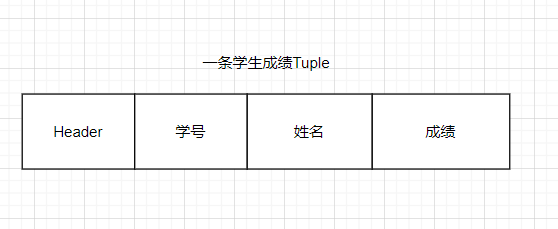
概览
内存管理器
索引
情景
在10000个学生的成绩表中(学号为1-10000),寻找你的编号(假如为7777)
- 你会从头找到尾吗?
BST 二叉搜索树
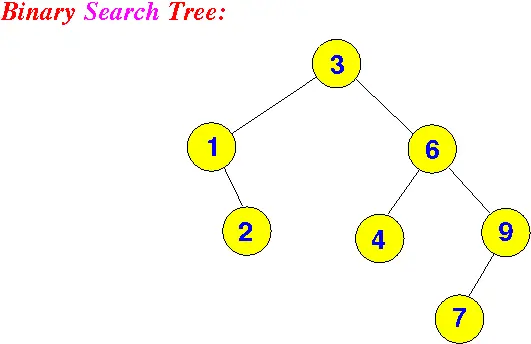
二叉搜索树的特性
为什么数据库不用二叉搜索树当索引
最坏的情况下磁盘的读写次数等于树的高度
B+树
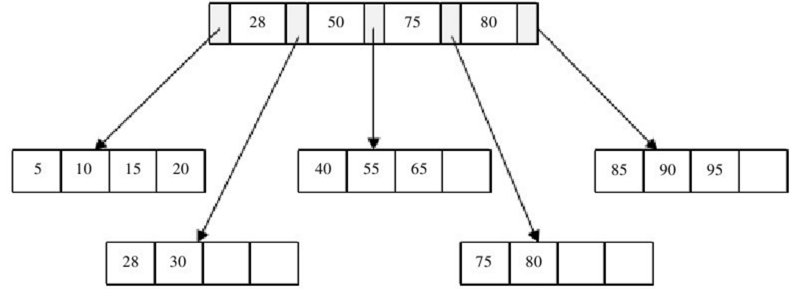
为什么要选用B+树
- 对于在磁盘上存储的索引文件,IO次数越少,效率越高。
比如BST对于1000条数据,高度为10。而B+树的高度为2。
执行引擎
常见的执行引擎模型
-
迭代模型/火山模型(Iterator Model)
-
物化模型(Materialization Model)
-
向量化/批处理模型(Vectorized / Batch Model)
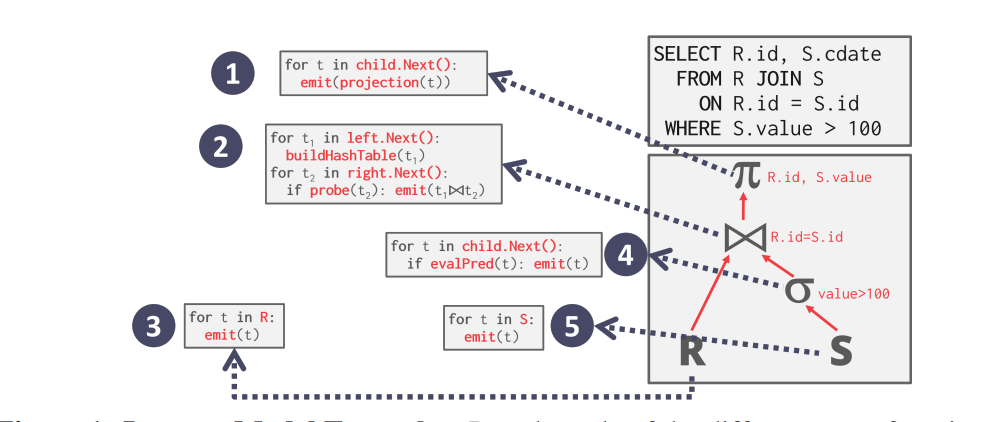
该计算模型将关系代数中每一种操作抽象为一个 Operator,将整个 SQL 构建成一个 Operator 树,查询树自顶向下的调用next()接口,数据则自底向上的被拉取处理。
火山模型的这种处理方式也称为拉取执行模型(Pull Based)。
大多数关系型数据库都是使用迭代模型的,如 SQLite、MongoDB、Impala、DB2、SQLServer、Greenplum、PostgreSQL、Oracle、MySQL 等。
火山模型的优点在于:简单,每个 Operator 可以单独实现逻辑。
火山模型的缺点:查询树调用next()接口次数太多,并且一次只取一条数据,CPU 执行效率低;而 Joins, Subqueries, Order By 等操作经常会阻塞。
事务
- 原子性(Atomicity):
- All-or-Nothing
- Before-or-After
- 一致性(Consistency): 事务执行的结果必须是使数据库从一个一致性状态变到另一个一致性状态。一致性与原子性是密切相关的。
- 隔离性(Isolation): 一个事务的执行不能被其他事务干扰。
- 持续性/永久性(Durability): 一个事务一旦提交,它对数据库中数据的改变就应该是永久性的。
以上是书面解释,简单来说就是把你的操作统一化,要么所有操作都成功,要么就都不成功,如果执行中有某一项操作失败,其之前所有的操作都回滚到未执行这一系列操作之前的状态。
事务的原语
- begin
- commit
- abort
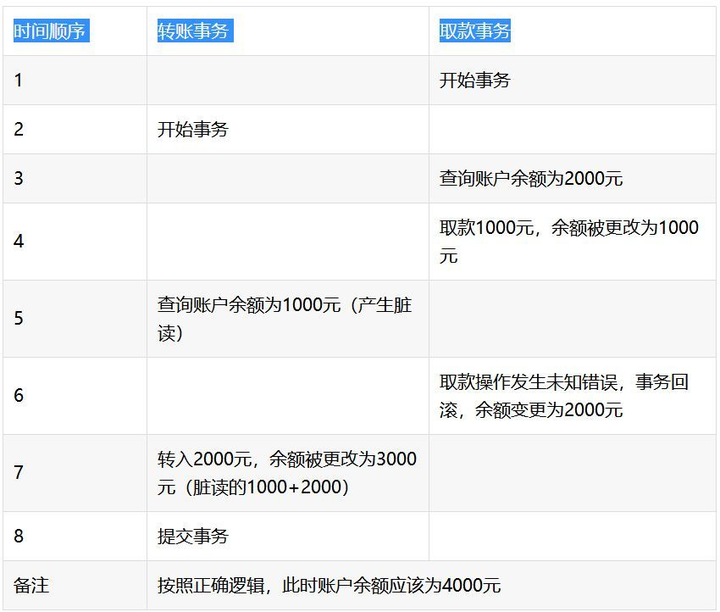
脏读
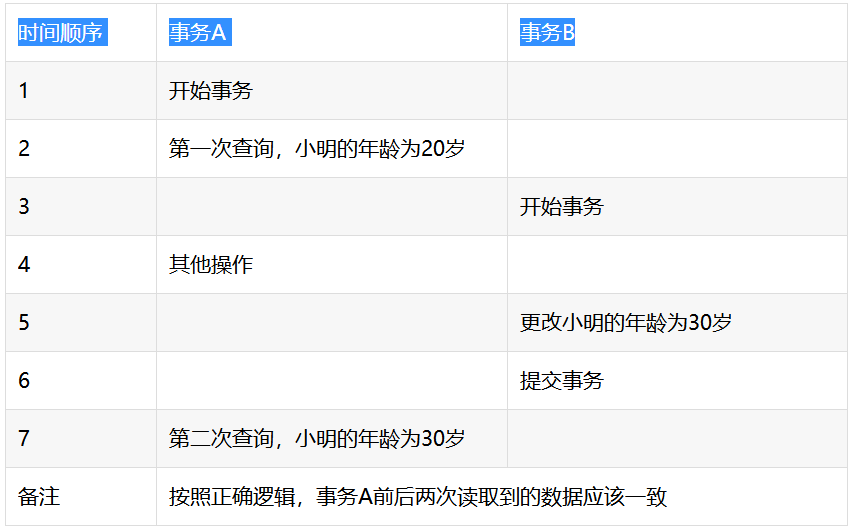
不可重复读
幻读
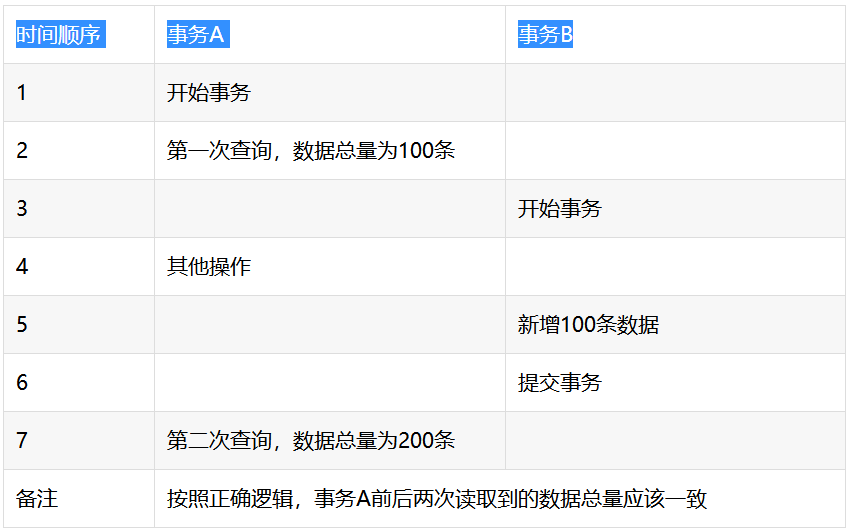
读写锁

通过锁简单实现事务
我们可以通过加表锁和行锁来实现之前的问题。
-
表锁:
- 当事务A对表1加读锁。
- 事务B可以对表1进行读操作,但是无法加写锁。
-
行锁:
- 假设表1中有5条记录。
- 事务A对第1,2条记录上写锁
- 事务B仍然可以尝试对其他记录上锁
事务的隔离级别
从弱到强
- RU: 读未提交
- RC: 读已提交(S大多数数据库的默认隔离级别)
- RR: 可重复读(MySQL的默认隔离级别)
- SE: 可序列化。隔离级别最强。
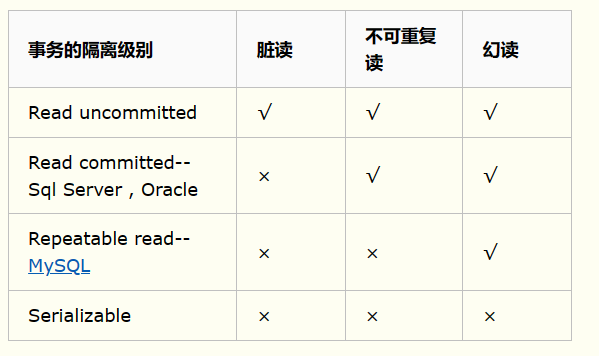
通过加锁实现不同的隔离级别
- RU:这里查询不加锁,但是增删改加了行级排他锁,直到事物被提交或回滚才会解锁。
- RC:事务读取的时候,查询操作尝试加共享锁。进行增删改时,会加行级排他锁,直到事物被提交或回滚才会解锁。
- RR:事务读取时加行级共享锁,直到事务结束才会释放。
- SE:事务读取时加表级排它锁,直到事务结束时,才释放。这里因为有一个串行化的一种状态,未触发前只可以进行查询操作,一旦进行增删改串行化就会被触发,增删改查都会被事务阻塞
隔离级别:读未提交
- 解决的问题:脏写
- 读不加锁 增删改加排他锁
- 存在的问题:脏读、不可重复读、幻读

隔离级别:读已提交
- 解决的问题:脏读
- 事务读取的时候,查询操作尝试加共享锁。进行增删改时,会加行级排他锁,直到事物被提交或回滚才会解锁。
- 存在的问题:不可重复读、幻读
不可重复读问题:
隔离级别:可重复读
- 解决的问题:脏读、不可重复读
- 存在的问题:幻读
幻读问题↓
故障恢复
日志系统
• UNDO: The process of removing the effects of an incomplete or aborted transaction.
• REDO: The process of re-applying the effects of a committed transaction for durability.
存储介质的分类
- 易失性存储。内存数据,断电后消失。
- 非易失性存储。比如你的磁盘。如果你的磁盘断电后,所有数据丢失后,是很可怕的。
- 稳定存储。一种不存在的非易失性存储形式,可在所有可能的故障情况下幸存下来。
非易失性存储器(NVMe)是一种半导体技术,不需要持续供电来保留存储在计算设备中的数据或程序代码。系统制造商出于各种目的使用不同类型的非易失性存储芯片。例如,一种类型的NVM可能存储诸如硬盘驱动器(HDD)和磁带驱动器等设备的控制器程序代码。另一种类型的NVM通常用于固态驱动器(SSD)、USB驱动器和数码相机、手机和其他设备中的存储卡中的数据存储。
一条LOG的结构
• Transaction ID.
• Object ID.
• Before Value (used for UNDO).
• After Value (used for REDO).
例如:
事务1,将表1的第二条记录修改了。之前的值是100,修改后的值为200。
Log File
| Log ID | 事务编号 | 操作对象 | Before Value | After Value | 其他 |
|---|---|---|---|---|---|
| 1 | T1 | BEGIN | |||
| 2 | T2 | BEGIN | |||
| 3 | T1 | 表1,记录1 | 100 | 200 | |
| 4 | T1 | ABORT | |||
| 5 | T2 | 表1,记录2 | 500 | 700 | |
| 6 | T2 | COMMIT |
内存替换策略
A steal policy dictates whether the DBMS allows an uncommitted transaction to overwrite the most recent
committed value of an object in non-volatile storage (can a transaction write uncommitted changes belonging to a different traansaction to disk?).
• STEAL: Is allowed Steal的优势:
• NO-STEAL: Is not allowed.
A force policy dictates whether the DBMS requires that all updates made by a transaction are reflected on
non-volatile storage before the transaction is allowed to commit (ie. return a commit message back to the
client).
• FORCE: Is required
• NO-FORCE: Is not required
DBMS需要确保以下保证:
• 一旦 DBMS 告诉某人它已提交,任何事务的更改都是持久的。
• 如果事务中止,则任何部分更改都不会持久。
窃取策略指示 DBMS 是否允许未提交的事务覆盖最新的 非易失性存储中对象的已提交值(事务可以写入属于 到另一个traansaction到磁盘?
• STEAL:允许 • NO-STEAL:不允许。
强制策略指示 DBMS 是否要求反映事务所做的所有更新 在允许事务提交之前进行非易失性存储(即将提交消息返回给 客户端)。 • FORCE:必填 • NO-FORCE:不需要 强制写入使其更容易恢复,因为所有更改都会保留,但会导致运行时间较差 性能
WAL
使用预写日志记录,DBMS在对磁盘页面进行更改之前,将对数据库所做的所有更改记录在一个日志文件中(在稳定的存储上)。日志包含足够的信息来执行必要的撤消和重做操作,以便在崩溃后恢复数据库。在将数据库对象刷新到磁盘之前,DBMS必须将对应于对数据库对象所做更改的日志文件记录写入磁盘。
通过WAL,可以实现STEAL + NO FORCE
也就是未提交事务的修改可以写到磁盘上,当事务提交时,也不用强制将修改写出到磁盘。
ARIES
对于日志中的所有记录
对于每个事务
- 如果该事务没有commit或abort,需要undo该事务。
- 否则redo该事务。
当数据库系统启动时,会进行恢复操作
- 重做阶段。redo
- 系统首先找到最后一个检查点,从前往后扫描并重做所有遇到的事务。
- 这个重做包括之前提到的CLR,也就是说,
<Ti,Xj,V1,V2>和<Ti,Xj,V2>都会重做Xj的值为V2。 - 这样,遇到了Abort就不再需要从后再往前扫描一遍了。
- 在redo阶段,需要维护一个活跃事务列表,该列表初值为Check point中的L,遇到commit或abort就会将L中的该事务去掉,遇到start就会在L中增加事务。
- 最后,会得到一个事务列表。undo-list
- 撤销阶段。undo
- 事务从后往前回滚所有undo-list中的事务。
- 请注意,CLR是不会被undo的。
- 具体操作和系统正常运行时abort掉的流程相似,当遇到start记录,从undo-list中删掉该事务,当list为空,undo阶段结束。
简要介绍ARIES的恢复算法

- 分析阶段
首先找到最后的checkpoint,获取脏页表。通过脏页表中最小的reclsn确定从哪个lsn开始重做。如果没有脏页,就将redolsn设置为checkpoint的lsn。也就是说,redo lsn之前的所有record都是已经确保写入了磁盘的。
在分析阶段,还需要维护undo-list,和undo-list中事务的lastLSN。
一旦分析阶段发现在页上更新的日志记录,还将更新脏页表。新的脏页的rec lsn为该log的lsn
- 重做阶段
通过从前往后扫描log。如果该log的页不在脏页表中,或者更新日志记录的LSN小于脏页表中该页的rec lsn(该log已经落盘),就跳过该次记录
否则就调出该页,如果该页的page lsn小于该日志的lsn,重做日志。
- 撤销阶段
撤销阶段会对日志进行反向扫描,并对undo list中的所有事务进行撤销。
如果遇到一个更新日志记录,就用其进行物理undo,并产生一条CLR,将该CLR的UndoNextLSN设置为该日志的prev LSN。
如果遇到一条CLR,说明在重做阶段已经进行了回滚操作,那么直接跳到UndoNextLSN就行。
分布式数据库
节点类型
同构节点:集群中的每个节点都可以执行相同的任务集(尽管可能 不同的数据分区),非常适合共享无架构。这使得预配 和故障转移“更容易”。失败的任务将分配给可用节点。
异构节点:为节点分配了特定任务,因此节点之间必须进行通信 执行给定的任务。可以允许单个物理节点托管多个“虚拟”节点类型,用于专用 任务。可以独立地从一个节点扩展到另一个节点。一个例子是MongoDB,它有路由器节点 将查询路由到分片和配置服务器节点,存储从键到分片的映射。
分区
分布式系统必须跨多个资源(包括磁盘、节点、处理器)对数据库进行分区。 此过程在 NoSQL 系统中有时称为分片。当 DBMS 收到查询时,它首先 分析查询计划需要访问的数据。DBMS 可能会发送 查询计划到不同的节点,然后合并结果以生成单个答案。
分区方案的目标是最大化单节点事务,或仅访问 包含在一个分区上的数据。这使得 DBMS 不需要协调并发的行为 在其他节点上运行的事务。另一方面,分布式事务在一个或 更多分区。这需要昂贵且困难的协调。对于逻辑分区的节点,特定节点负责从共享访问特定元组 磁盘。对于物理分区的节点,每个共享的 nothing 节点都会读取并更新其在其上包含的元组 自己的本地磁盘。
实现
对表进行分区的最简单方法是朴素的数据分区。假设足够了,每个节点存储一个表 给定节点的存储空间。这很容易实现,因为查询只是路由到特定的 分区。这可能很糟糕,因为它不可扩展。如果一个分区的资源耗尽,则该分区的资源可能会耗尽 经常查询表,而不是使用所有可用的节点。有关示例,请参见图 2。 另一种分区方法是垂直分区,它将表的属性拆分为单独的分区。 每个分区还必须存储用于重建原始记录的元组信息。
更常用的是水平分区,它将表的元组拆分为不相交的子集。选择 根据大小、负载或使用情况平均划分数据库的列,称为分区键
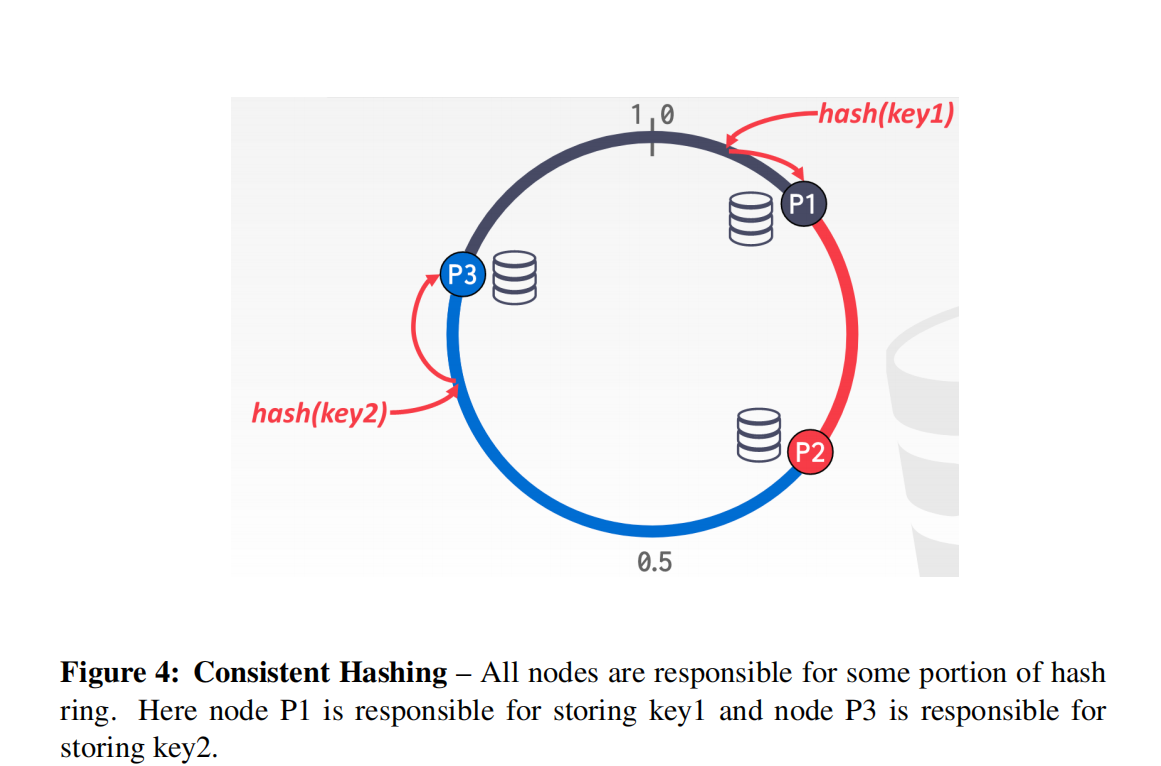
DBMS 可以通过哈希分区或范围分区对数据库进行物理分区(无共享)或逻辑分区(共享磁盘)分区。有关示例,请参见图 3。哈希分区的问题在于,当 添加或删除新节点,需要对大量数据进行洗牌。对此的解决方案是一致的 散列法。 一致性哈希将每个节点分配到某个逻辑环上的某个位置。然后是每个分区的哈希值 键映射到环上的某个位置。顺时针方向上最接近键的节点是 负责该密钥。有关示例,请参见图 4。添加或删除节点时,键仅 在与新节点/删除的节点相邻的节点之间移动。复制因子 n 表示每个键 按顺时针方向在 n 个最近的节点处复制。