一致性的基本问题
讨论“一致性”时,经常遇到强一致、弱一致、线性一致、可串行化、最终一致、因果一致…这些词。对工程分析来说,更直接的切入方式通常是下面三个问题:
- 我刚写进去的数据,别人什么时候能读到?
- 两个并发操作同时发生时,系统的预期结果和实际结果可能是什么样的?
- 数据在多个系统之间流转时,下游看到的是不是同一个版本?
这三个问题指向了三个不同的层面:
- 副本层:同一份数据有多个副本时,读到的是不是最新的(写完以后别人多久能看到)。
- 事务层:多个并发操作放在一起,结果还能不能解释成一个合理顺序(库存会不会扣成负数)。
- 跨系统层:缓存、数据库、对象存储、湖仓、数仓接在一起以后,系统整体的一致性(报表和主库对不对得上)。
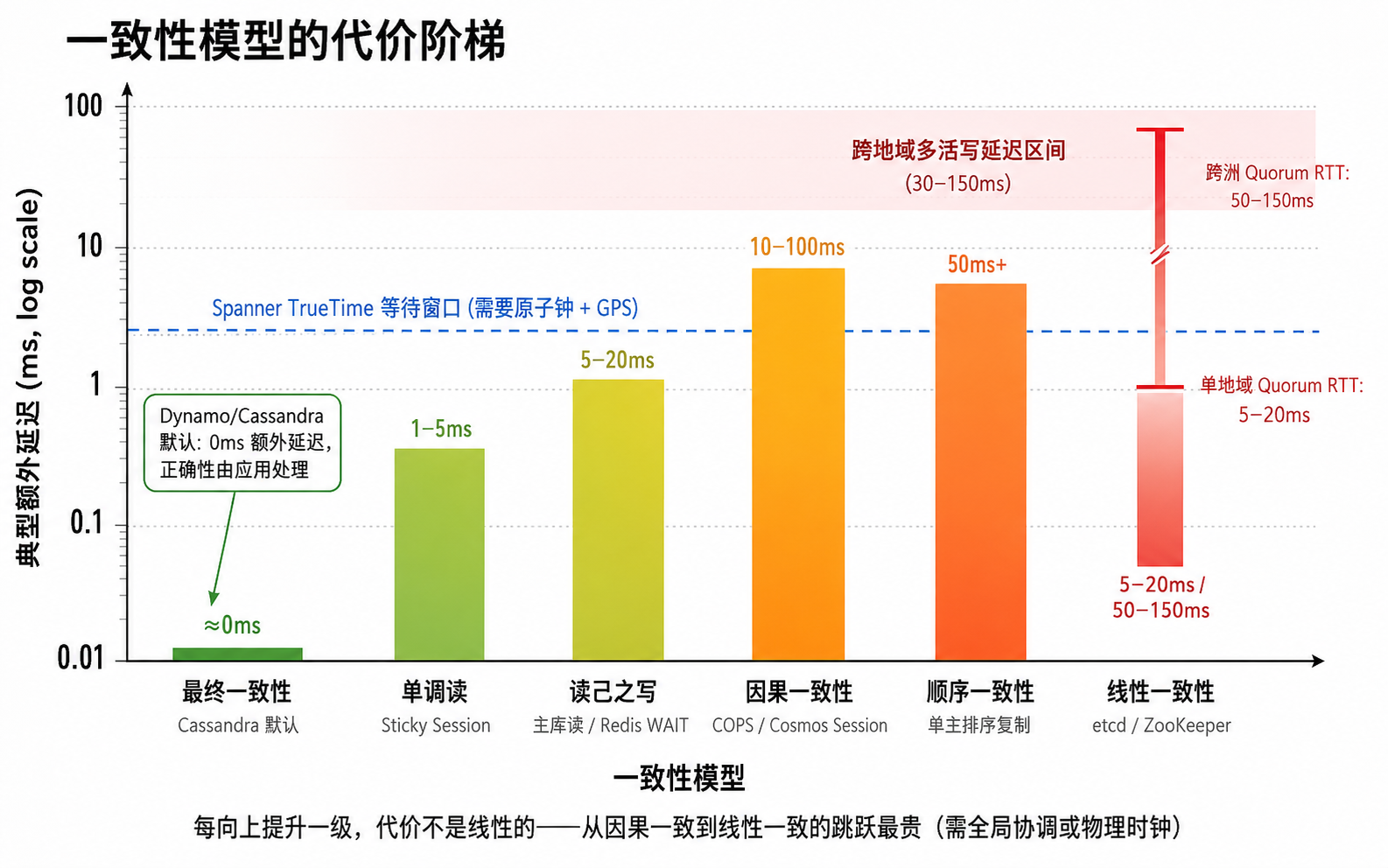
Jepsen 的定义适合作为起点:一致性模型本质上规定的是系统允许哪些操作历史是”合法的”1。工程实现中,还需要把系统为维护该合法性付出的代价纳入考量——一致性从来不是免费的,要么在写入时等待更多副本确认,要么在提交时做冲突检测,要么将复杂度抛给应用层。PACELC 将这种权衡概括为:即使没有网络分区,系统日常也要在延迟和一致性之间做选择2。
提示
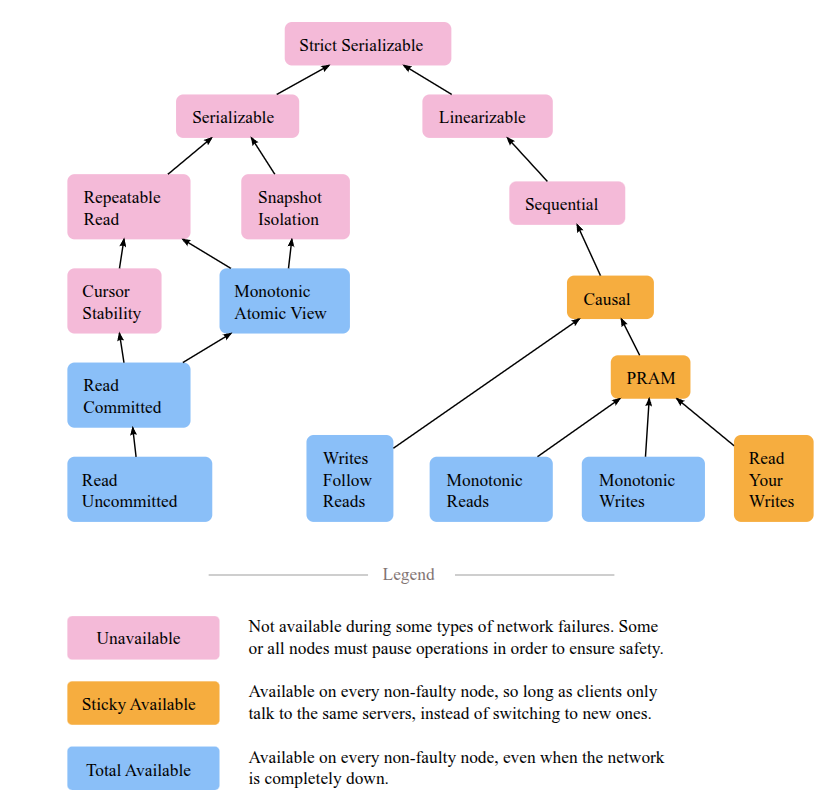
一致性模型的分类法
讨论具体系统之前,先做一个关键区分:一致性模型(consistency model)和隔离级别(isolation level)是两件正交的事。
- 一致性模型定义"同一份数据有多个副本时,读操作能看到什么值"。研究对象是复制协议。输入是一组读写操作的历史,输出是"这个历史是否合法"。
- 隔离级别定义"多个数据项上的并发事务如何相互影响"。研究对象是并发控制。输入是一组事务的交错执行,输出是"这个执行是否等价于某种串行顺序"。
备注混淆的根源在于两者都用了"一致"这个词。“强一致"通常指向副本层的线性一致;“可串行化"是事务层的最高隔离级别。一个有线性一致读的系统可以完全不支持跨行事务(如 HBase);一个可串行化的数据库在异步复制下副本层只是最终一致(如单机 PostgreSQL + 流复制)。
下面从强到弱展开这些模型。它们之间存在严格的包含关系:线性一致 ⊃ 顺序一致 ⊃ 因果一致 ⊃ PRAM ⊃ 最终一致。
线性一致性(Linearizability)
定义来自 Herlihy & Wing (1990):每个操作看起来在其调用与返回之间的某个瞬间原子地完成;存在一个与实时时钟一致的操作全序;任何读操作返回该全序中最近一次写入的值5。
这是 CAP 定理中 C 的严格含义——CAP 的 C 是 atomic consistency,就是线性一致,不是笼统的"数据不错乱”。
翻译成工程语言:一个写操作返回"成功"之后,所有节点上的所有读请求都必须看到这个写入的值。只要有一个读返回旧值,系统就不是线性一致的。
代价:写操作必须等待多数派确认。跨地域部署时,每次写入至少等一个洲际往返。Google Spanner 用 TrueTime(原子钟 + GPS)把"等通信"换成了"等时钟不确定性窗口过去”——代价没有消失,只是从网络延迟换成了时钟同步等待6。
典型实现:Spanner(外部一致性本质上就是线性一致)、etcd / Consul / ZooKeeper(共识层)、HBase STRONG 读。
顺序一致性(Sequential Consistency)
定义来自 Lamport (1979):所有处理器的操作看起来按某个全局顺序逐个执行,每个处理器内的操作按其程序顺序出现在该全局序中7。不要求全局序与实时时钟一致。
与线性一致的唯一区别:A 和 B 并发执行时,即使 B 在实时上先返回,系统也可以声称全局序是 A → B。工程中很少有系统仅提供顺序一致而不提供线性一致,其主要价值是理论层级中的参照点。
因果一致性(Causal Consistency)
如果写操作 B 依赖了写操作 A 的结果(读了 A 的值然后产生了 B),所有节点必须按 A → B 的顺序看到这两个写。没有因果关系的并发写可以以不同顺序出现在不同副本上,只要最终收敛8。
这比线性一致便宜得多:不需要全局协调,只需要在消息中携带依赖集(vector clock),接收方延迟不满足因果序的操作直到依赖到达。
典型实现:COPS、Eiger、MongoDB causally consistent sessions。
提示在最终一致的系统中,可能出现"回复出现在原帖之前"的反直觉乱序——因果一致禁止这种行为。
会话保证(Session Guarantees)
Terry et al. (1994) 提出了一组面向单客户端会话的保证,比因果一致更弱但比裸最终一致实用9:
读写一致性(Read-Your-Writes):会话写入后,自己的后续读一定看到该写入。不会出现"我刚发的评论,刷新就没了"。
单调读(Monotonic Reads):读到的值不会"倒退"。如果已经读到时间点 t,后续读不会返回比 t 更旧的版本。
单调写(Monotonic Writes):同一会话内的写按其发出顺序被系统序列化。
PRAM / FIFO 一致性:同一进程的写被所有其他进程按该进程的写顺序看到。不同进程间的写可以任意交织。PRAM = 单调读 + 单调写 + 读写一致 + 写后读(Writes-Follow-Reads)。
最终一致性(Eventual Consistency)
如果不再有新写入,经过足够长的时间后,所有副本最终收敛到同一个值。不承诺收敛时间,不承诺收敛过程中读到什么。DNS、CDN、Cassandra 默认模式均在此列。
Dynamo 的关键贡献在于把收敛窗口设计为可调参数(R + W > N → 逼近强一致),由应用侧控制收敛时间10。
总结
| 模型 | 核心约束 | 典型实现 |
|---|---|---|
| 线性一致 | 全局实时全序;写入返回后所有读可见 | Spanner, etcd/ZK, HBase STRONG |
| 顺序一致 | 全局全序,不要求实时序 | 主要是理论参照 |
| 因果一致 | 有因果的写有序;并发写可不同序 | COPS, MongoDB causal sessions |
| PRAM | 同进程写被全部节点按序看到 | 会话保证的组合 |
| 读写一致 | 自己写的自己能读到 | Redis WAIT 逼近、多数派读写 |
| 单调读 | 读不会退回到更旧版本 | sticky session、多数派读 |
| 最终一致 | 停止写入后最终收敛 | Redis 默认、Cassandra 默认、DNS |
关系数据库:优先保护事务不变量
核心目标是提交时正确
关系数据库的核心目标是多表事务的一致性:
在事务提交的那一刻,数据就已经满足业务约束。
PostgreSQL 用 MVCC 提供快照读,减少读写冲突;MySQL InnoDB 用一致性读和锁来控制并发;Oracle 通过 undo 提供读一致性41112。
实现手段各有不同——PostgreSQL 用 MVCC 做快照读(读不阻塞写),MySQL InnoDB 在 REPEATABLE READ 下基于首次读建立快照,Oracle 通过 undo 保留旧版本——但目标一致:查询看到的是一张自洽的快照,并发修改不破坏快照的前后一致性4111213。
副本层与事务层的分离
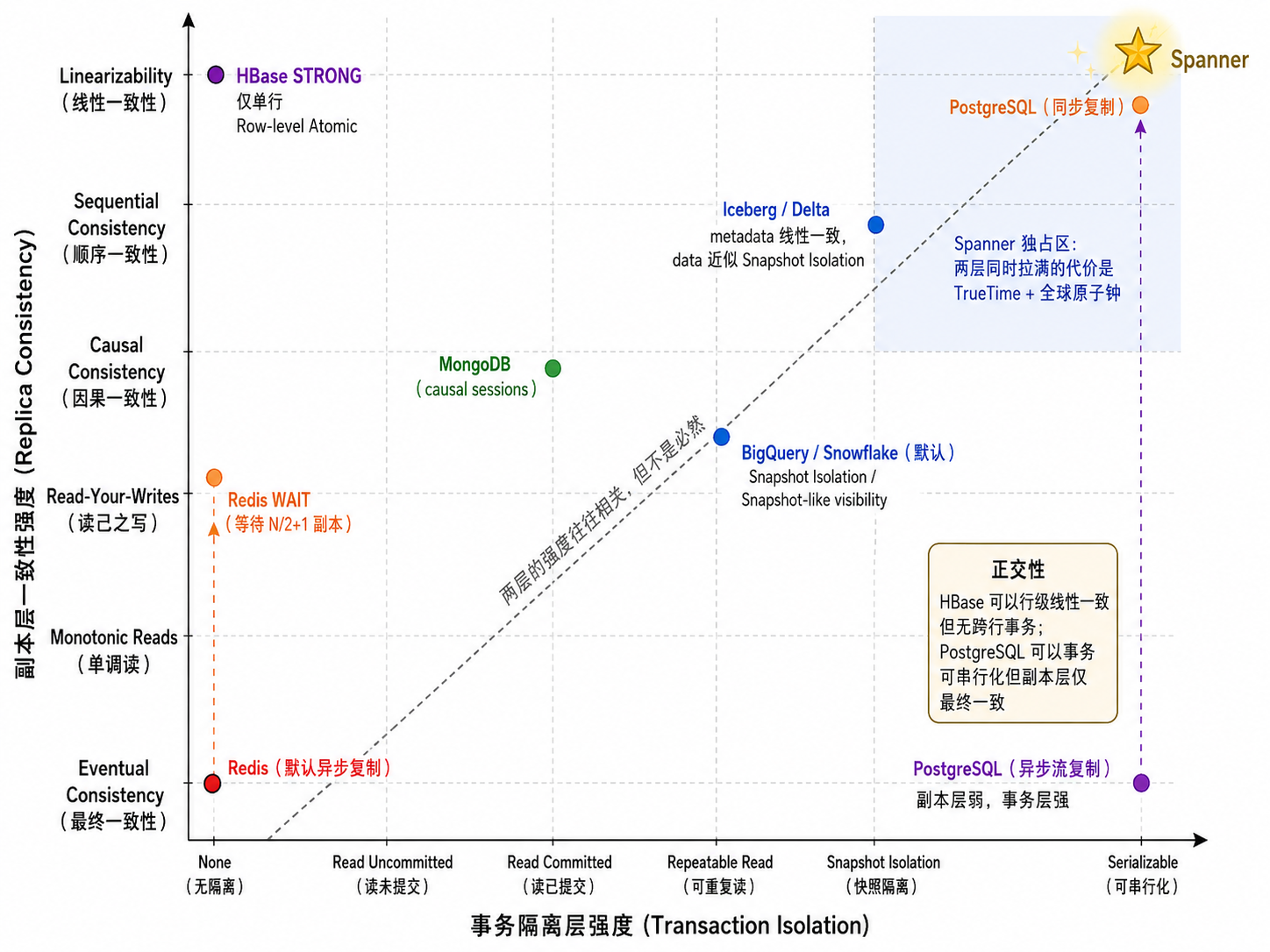
关系数据库在单机模式下天然线性一致——所有读写经过同一个状态机。一旦引入主从复制,副本层语义立即变化:异步流复制退化为最终一致(PostgreSQL / MySQL 默认模式),同步复制可在两个副本范围内逼近线性一致,代价是每个提交多等一个网络 RTT。两层互不冲突——关系数据库的"强"在事务层,副本层的强弱取决于复制配置。
KV 系统:在低延迟与正确性之间取舍
KV 系统内部差异很大,”KV 就是最终一致”是常见的误解。同样是 KV,Redis 和 HBase 的默认取舍截然不同。
Redis:优先保护低延迟
默认复制策略的重点
Redis 默认复制是异步的。主节点写入成功不表示所有副本此刻都已追上。WAIT 命令可以让客户端等待指定数量的副本确认,但 Redis 文档明确指出:WAIT 仅提升数据安全性,不会把 Redis 变成强一致事务数据库3。
对应的副本层语义:默认最终一致,WAIT 可将其拉到接近读写一致,但不会变成线性一致。
以商品库存为例:库存只剩 1 件,两次购买请求并发到达。Lua 脚本和原子操作可应对单键扣减,但一旦扩大到多键约束、跨表约束、故障切换后数据不丢,问题性质就变了——此时要求的是事务层保证(扣减和订单一起成功或失败),而这超出 Redis 的设计范围。Redis 的策略是优先低延迟、异步确认:如果业务允许短时间读到旧数据,这一复制策略可获取高吞吐;如果要求提交时即满足多对象约束,PostgreSQL 才是正确选择。
HBase:优先保护行级正确性
HBase 则代表了 KV 系统的另一种路径。客户端提供 Consistency.STRONG 和 Consistency.TIMELINE 两个选项:默认强一致读(行级线性一致——对同一行的读无论落在哪个 RegionServer 都返回最新已提交值),选择 TIMELINE 时以可能读到陈旧数据换取更低尾延迟1415。这与 Redis 构成根本差异:Redis 默认优先低延迟,HBase 默认优先行级正确性。
HBase 的适用边界很清晰:大规模表上的行级读写,要求单行语义稳定、读延迟可控(日志画像、宽表明细、按主键读取的大表服务)。它不适合承接通用多事务不变量。
数据仓库 / OLAP:优先保护查询快照
一致性目标与 OLTP 不同
数仓系统对一致性有自己的侧重点,它优先保护的对象与 OLTP 不同。
BigQuery 和 Snowflake 都有清晰的一致性语义,只是它们最在意的不是“每次写入立刻对所有会话可见”,而是:
- 一次分析查询看到稳定快照;
- 大吞吐查询不要被高冲突小事务拖垮。
BigQuery 文档说明它支持多语句事务,隔离级别为 snapshot isolation;但如果事务读取外部数据源,底层数据变化时一致性边界即被打破16。
仓库内部尽可能提供稳定语义,跨越到外部数据源时,一致性边界自然弱化。
BigQuery 和 Snowflake 在事务层提供快照隔离(Snapshot Isolation),一次查询看到某个时间点的稳定快照。Snowflake 将跨 session 可见性暴露为可调参数——默认 READ COMMITTED 且不保证并发变更立刻可见,将 READ_CONSISTENCY_MODE 设为 GLOBAL 后可逼近线性一致,代价是额外几毫秒延迟171819。这里的”一致”指的是表版本对所有 session 是否立刻可见,不是 OLTP 的行级线性一致。
以日报查询为例:它扫描大量分区和长周期数据,核心风险不是”某一行晚 30 毫秒”,而是查询扫到一半表版本变了、分析任务看到混合状态、高并发更新卡住全平台。因此数仓将资源优先投给快照稳定、大吞吐和并发隔离,而非实时写入可见性。
一致性不是二值的”有或无”,而是可配置、可定价的连续谱。OLAP 系统追求的是”分析时读到完整快照”,不是”写入后所有人立刻同步可见”。
数据湖仓:优先保护表快照
核心问题是快照是否完整切换
在 Iceberg、Delta Lake 这类系统中,一致性问题的重心从行级转移到了表级。
湖仓中一张表的物理存储不是单个文件,而是一组数据文件、manifest、metadata 文件的集合。真正要保证的一致性不是”某一行是否最新”,而是:
读者看到的,是不是同一个表版本。
即使底层对象存储已提供强一致性保证——S3 目前对对象读写和列表操作均提供强一致——也不等于系统自动获得”表级 ACID”2021。对象存储保证单 key 写入原子性和写完立即可读,但多个数据文件同时生效、metadata 指针原子切换、并发写冲突处理均不在其职责范围内。这正是 Iceberg 和 Delta 在元数据层做的事。
Iceberg 和 Delta 的基本做法
Iceberg 和 Delta 的核心策略一致:
- 先将新数据文件写入。
- 再生成新的 metadata。
- 最后将”当前表版本指针”原子切换到新快照。
Iceberg 文档对此有清晰的说明:通过原子替换 metadata 文件位置,实现 serializable isolation 和 snapshot-based reading2223。Delta Lake 也是类似思路:先读当前快照,再写新文件,最后做 validate-and-commit,如果中间有人先提交了,就冲突重试24。
在一致性模型层面,Iceberg 和 Delta 在元数据层提供可串行化的快照隔离(Serializable Snapshot Isolation)。metadata 指针的原子 swap 是一次线性一致的操作——所有读者要么看到旧快照,要么看到新快照,没有中间态。但数据文件本身没有行级锁,高并发修改的冲突解决策略是乐观并发控制(OCC)加重试。这与关系数据库的悲观锁代表了两种不同的并发策略:前者假设冲突少、发生后重试;后者假设冲突多、提交前先阻塞。
适用边界
快照切换保证读者要么看到旧版本,要么看到新版本,不会读到”拼到一半的表”。代价是:一致性集中在元数据提交这一步,高并发 UPDATE、DELETE、MERGE 时冲突显著增多(Delta 文档专门列出哪些操作对会冲突24)。因此湖仓适合批量摄取、CDC 回放、大规模分析、时间旅行、多引擎共享一张表;替代订单主库承接高冲突 OLTP 则超出设计范围。
湖仓系统优先保证”整张分析表始终自洽”,而非单条写入的实时可见。
把几类系统放在一起看
| 系统 | 副本层一致性模型 | 事务/隔离层保证 | 主要代价 | 最适合的场景 |
|---|---|---|---|---|
| PostgreSQL / MySQL / Oracle | 取决于复制配置(默认最终一致,同步复制可逼近线性一致) | 快照隔离 / 可串行化 | 并发控制、锁、死锁检测、冲突重试 | 订单、支付、库存、账务 |
| Redis | 默认最终一致(WAIT 可逼近读写一致) | 无跨键事务 | 把部分正确性压力留给应用层 | 缓存、登录态、热点计数 |
| HBase | 行级线性一致(STRONG);最终一致(TIMELINE) | 行级原子性 | 读路径选择与副本同步管理 | 大表行级强一致访问 |
| BigQuery / Snowflake | 快照隔离(跨 session 可调至逼近线性一致) | 快照隔离 | 跨会话可见性延迟、外部数据边界 | 报表、ETL、ad-hoc 分析 |
| Iceberg / Delta | 元数据层可串行化快照隔离(线性一致的 metadata swap) | 快照隔离 | 提交阶段 OCC 冲突重试 | 湖仓分析、CDC、时间旅行 |
验证一致性:如何测试系统声称的保证
文档声称的语义与实际实现之间可能存在差距。以下工具和方法论用于在测试环境中复现和验证系统的一致性行为。
Jepsen:分布式一致性的系统性验证
Jepsen 是目前最系统化的一致性测试框架。核心方法:对被测系统注入故障(网络分区、时钟偏斜、进程崩溃),同时执行随机读写操作并记录完整操作历史,最后用形式化检查器验证该历史是否符合目标一致性模型。
Jepsen 的测试覆盖三个维度:
- 线性一致性检查(Knossos):给定读写操作历史和全局时间戳,检查是否存在一个与实时序兼容的操作全序。问题本身是 NP-hard,但 Knossos 在实际操作历史上通常足够高效。
- 事务隔离检查(Elle):通过构造特定模式的读写依赖图检测事务异常(G2-item、G-single、lost update 等)。不依赖系统内部状态,纯粹从外部观测推断隔离级别。
- 故障注入(Nemesis):模拟网络分区(iptables)、时钟偏斜(
libfaketime)、节点崩溃(kill -9)、磁盘满等故障。
Jepsen 的分析覆盖了 PostgreSQL、Redis、MongoDB、etcd、Kafka、ZooKeeper 等大多数主流数据库,公开分析报告是理解各系统一致性边界的重要一手资料。
轻量级验证工具
Porcupine:Go 实现的线性一致性检查器,接受操作历史 JSON,输出合法/非法判断。etcd 和 TiKV 将其集成在 CI 中作为线性一致性回归测试(Porcupine)。适合嵌入现有 Go 测试框架。
Hermitage:专门测试事务隔离级别(而非副本层一致性)。通过构造特定的并发事务序列来区分不同隔离级别,覆盖 PostgreSQL、MySQL、CockroachDB 等(Hermitage)。如果目标是确定”当前事务配置到底是什么隔离级别”,Hermitage 比 Jepsen 更直接。
Maelstrom:Fly.io 维护的分布式系统教学与测试平台,底层复用 Jepsen 的线性一致性检查器,用 Edn 协议定义节点间消息格式(Maelstrom)。适合在学习阶段或新项目早期快速验证协议设计。
混沌工程工具
Jepsen 定位为一次性深度分析,混沌工程工具则侧重在类生产环境中持续注入故障以暴露一致性薄弱点。
Chaos Mesh:CNCF 项目,运行在 Kubernetes 上。可注入 Pod 故障、网络故障(延迟、丢包、重复、乱序)、IO 故障、时钟偏斜(Chaos Mesh)。TimeChaos 类型可直接修改容器内时钟,是测试线性一致性(依赖实时序语义)的有效手段。
Chaos Monkey:Netflix 开发的最早的混沌工程工具,通过随机终止生产实例验证服务降级路径(Chaos Monkey)。粒度粗(仅做实例终止),但理念是整个混沌工程的起点:不假设依赖永远是健康的。
Litmus:Kubernetes 原生的混沌工程框架,提供声明式故障注入和”混沌工作流”的概念,适合在 CI/CD 中编排多步骤的一致性验证场景(Litmus)。
形式化验证:TLA+ 与确定性模拟
测试只能证明错误存在,形式化方法可以在模型内部证明错误不存在。
TLA+:Lamport 设计的规约语言,用于对并发和分布式协议建模并做 model checking。MongoDB 的复制协议、AWS S3 的一致性设计、Azure Cosmos DB 都公开发表过 TLA+ 规约(TLA+)。它的定位是设计阶段的验证方法,而非测试工具。
FoundationDB 确定性模拟器:FoundationDB 团队未使用 Jepsen 或运行时混沌测试,而是写了一个单线程确定性模拟器,将整个数据库——包括网络、磁盘、时钟——作为确定性状态机运行(FoundationDB Testing)。所有随机种子可控,任何非确定性 bug 都能完美复现。这套方案在 bug 发现率和复现效率上显著优于传统随机测试。
备注形式化验证和确定性模拟的共性:它们不在真实环境中运行,而是将被测系统约束在一个可控的、确定性沙箱里。牺牲了环境真实性,换取了 bug 的确定性复现和异常路径的系统性覆盖。
实践路径
- 数据库选型阶段,先阅读 Jepsen 对该系统的公开分析报告,确认其声称的一致性模型是否已被验证过,以及在哪些故障条件下出现了一致性退化。
- 在已有系统中引入新数据组件,用 Porcupine 或 Hermitage 构建针对性的回归测试,集成到 CI 中。
- 运维阶段,在预发布环境中用 Chaos Mesh 或 Litmus 持续注入故障,监测一致性相关指标(复制延迟、事务冲突率、读写异常数)。
- 设计新的分布式协议,先用 TLA+ 建模验证正确性,再投入实现。
如何选型与如何看待”强一致”
选型时,搁置”要不要强一致”这个粗糙的二分法,先回答三个问题:
问题一:更怕旧数据,还是更怕业务算错 “晚几秒看到”通常不是事务层问题;”多卖一件货、扣错一笔钱”首先要检查事务隔离级别。
问题二:能否接受冲突重试 湖仓的常见问题不是计算错误,而是并发写冲突后需要重试。批处理容忍度高时这一模型匹配良好;点一下按钮就要即时反馈成败的场景,约束完全不同。
问题三:一致性边界是否已经跨系统 很多团队单独评估 PostgreSQL(事务层优秀)、Redis(低延迟)、数仓(高吞吐)都没问题,真正脆弱的环节在衔接处——主库提交了、缓存还没更新、CDC 还没同步、报表已经开始读了。
脱离上下文说”这个系统强一致”是对这个词最大的滥用。真正有用的提问是:它对什么对象强?在什么边界内强?要付出什么代价?跨系统后保证还剩多少?
一致性并非单一指标,它是系统对”读到什么、按什么顺序发生、在哪个边界内成立”所做的一组承诺。工程上的优先级不是追求”最强”,而是先看清保护对象,再决定把代价花在哪个层。
-
Jepsen, “Consistency Models”. https://jepsen.io/consistency/models ↩︎
-
Daniel J. Abadi, “Consistency Tradeoffs in Modern Distributed Database System Design: CAP is Only Part of the Story”. https://www.cs.umd.edu/~abadi/papers/abadi-pacelc.pdf ↩︎
-
Redis documentation,
WAITcommand. https://redis.io/docs/latest/commands/wait/ ↩︎ ↩︎ -
PostgreSQL documentation, MVCC / concurrency control. https://www.postgresql.org/docs/current/mvcc.html ↩︎ ↩︎ ↩︎
-
Herlihy & Wing, “Linearizability: A Correctness Condition for Concurrent Objects”. https://cs.brown.edu/~mph/HerlihyW90/p463-herlihy.pdf ↩︎
-
Google Cloud Spanner documentation, TrueTime and external consistency. https://cloud.google.com/spanner/docs/true-time-external-consistency ↩︎
-
Lamport, “How to Make a Multiprocessor Computer That Correctly Executes Multiprocess Programs”. https://lamport.azurewebsites.net/pubs/multi.pdf ↩︎
-
Ahamad et al., “Causal Memory: Definitions, Implementation, and Programming”. https://link.springer.com/article/10.1007/BF01784241 ↩︎
-
Terry et al., “Session Guarantees for Weakly Consistent Replicated Data”. https://people.eecs.berkeley.edu/~brewer/cs262b/terry-session.pdf ↩︎
-
DeCandia et al., “Dynamo: Amazon’s Highly Available Key-value Store”. https://www.allthingsdistributed.com/files/amazon-dynamo-sosp2007.pdf ↩︎
-
MySQL documentation, InnoDB consistent nonlocking reads. https://dev.mysql.com/doc/refman/8.1/en/innodb-consistent-read.html ↩︎ ↩︎
-
Oracle Database Concepts, data concurrency and consistency. https://docs.oracle.com/en/database/oracle/oracle-database/19/cncpt/data-concurrency-and-consistency.html ↩︎ ↩︎
-
Oracle documentation, undo and read consistency. https://docs.oracle.com/html/E25494_01/undo001.htm ↩︎
-
Apache HBase API,
Consistencyenum. https://hbase.apache.org/2.3/apidocs/org/apache/hadoop/hbase/client/Consistency.html ↩︎ -
Apache HBase Reference Guide, timeline consistency. https://hbase.apache.org/1.1/book.html#timeline.consistency ↩︎
-
BigQuery documentation, multi-statement transactions. https://cloud.google.com/bigquery/docs/transactions ↩︎
-
Snowflake documentation, transactions and read consistency across sessions. https://docs.snowflake.com/en/sql-reference/transactions ↩︎
-
Snowflake documentation,
READ_CONSISTENCY_MODEparameter. https://docs.snowflake.com/en/sql-reference/parameters ↩︎ -
Snowflake documentation,
LOCK_WAIT_HISTORYview. https://docs.snowflake.com/en/sql-reference/account-usage/lock_wait_history ↩︎ -
Amazon S3 User Guide, data consistency model. https://docs.aws.amazon.com/AmazonS3/latest/userguide/Welcome.html ↩︎
-
AWS News Blog, “Amazon S3 Update – Strong Read-After-Write Consistency”. https://aws.amazon.com/blogs/aws/amazon-s3-update-strong-read-after-write-consistency/ ↩︎
-
Apache Iceberg documentation, reliability. https://iceberg.apache.org/docs/1.9.0/reliability/ ↩︎
-
Apache Iceberg specification. https://apache.github.io/iceberg/spec/ ↩︎
-
Delta Lake documentation, concurrency control. https://docs.delta.io/latest/concurrency-control.html ↩︎ ↩︎